Vor knapp 3 Jahren musste ich bereits meine Grafikkarte erneuern, da meine gute alte Zotac GTX460 *hust* das zeitliche gesegnet hat. Zu dem Zeitpunkt waren natürlich Grafikkarten vom Preis her extrem teuer und auch schwierig zu bekommen (Corona lässt grüßen). So wurde es damals eine Nvidia 1650 OC von Asus, die ich auch weiterhin in Betrieb lasse. Für meine Ansprüche ist sie ausreichend und sie läuft.
Das Gehäuse hab ich mittlerweile seit meinem AMD Athlon 64 X2 6400+. Das war… ca vor 20 Jahren. Ganz genau könnte ich das jetzt nicht sagen, aber es ist alt. Das Gehäuse ist noch ein gutes, altes Stahlblech-Gehäuse im damaligen Skytower-Format. Da hat man Platz drin. Zwei Festplattenkäfige für jeweils 3 3.5’’ Festplatten, dazu noch 4 Einschübe für 5¼ Laufwerke und 2 Einschübe für 3.5’’ Laufwerke. Die darein gehörenden Disketten- und CD Laufwerke gibt es schon lange nicht mehr, aber denen trauere ich nicht hinterher. Nachträglich hab ich an der Frontplatte einen Multicard-Reader eingebaut und das gesamte Gehäuse von innen gedämmt, damit man nichts mehr hört. Das Ding hält vermutlich noch 100 Jahre und so behalte ich das natürlich auch noch.
Das Ergebnis ist schließlich diese Tabelle:
| Hardware | ALT | NEU |
|---|---|---|
| CPU | Intel Core I5 6600K | AMD Ryzen 9 7900X |
| Mainboard | Asrock Z170 Pro 4S | ASUS TUF Gaming X670E-Plus |
| CPU Kühler | EKL Alpenföhn Brocken ECO Tower | Be Quiet Dark Rock Elite |
| RAM | 16GB (4x 4GB) Crucial DDR4-2133 | 32 GB (2x 16GB) AData Lancer XMP DDR5-5200 |
Zusätzlich noch eine M.2 SSD WD Black SN850X mit 4TB. Ich hatte zwar vorher auch nur noch SSDs in Betrieb und werde die auch übernehmen, aber als Haupt-Laufwerk hab ich mir das eingeblidet.

Der Umbau
Da will ich jetzt gar nicht soviel drüber schreiben. Ich glaub, es gibt im Internet schon genügend Diskussionen darüber, ob man die Wärmeleitpaste (da lag beim Kühler übrigens auch eine dabei) per Tröpfchen-Technik aufträgt oder gleichmäßig mit irgendwas verteilt.
Ich möchte lediglich ein Bild zeigen:

Ja, das ist mein alter Lüfter. Links hab ich bereits leicht abgesaugt, rechts ist noch original… Ich hab in meinem Gehäuse eigentlich Staubfilter drin, aber wenn man das jetzt so sieht, sollte man doch gelegentlich mal den Rechner aussaugen.
Ansonsten hier ein paar Bilder, wie das Teil fertig aussieht



Ein paar kleine Anekdoten kann ich hier noch schreiben:
Meine ursprüngliche Isolierung musste ich zum Großteil entfernen, weil der Kühler viel zu groß ist. Er passt jetzt wirklich auf den Millimeter hinein. Da der Lüfter aber ohnehin so leise ist, bereue ich das auch nicht.
Des Weiteren war es eine lustige Sache: Alles leuchtet und blinkt (das Schlimmste ist der Kühler übrigens) und ich denk mir dabei: “Wenn ich fertig bin, mach ich die Klappe zu und man sieht nichts mehr davon. Ja… ich hab die ganzen LEDs dann im Bios deaktiviert, weil ich die wirklich nicht benötige.
Performance
Der viel interessantere Teil ist jetzt vermutlich wie sich die Performance verändert hat.
Also zum Einen hab ich mit Cinebench einen Benchmark ausgeführt. Mit dem alten System kam ich auf folgende Werte:
| CPU (Multi Core) | 128 pts |
| CPU (Single Core) | 57 pts |
Also Vergleich dazu hier die neuen Zahlen:
| CPU (Multi Core) | 28726 pts |
| CPU (Single Core) | 1980 pts |
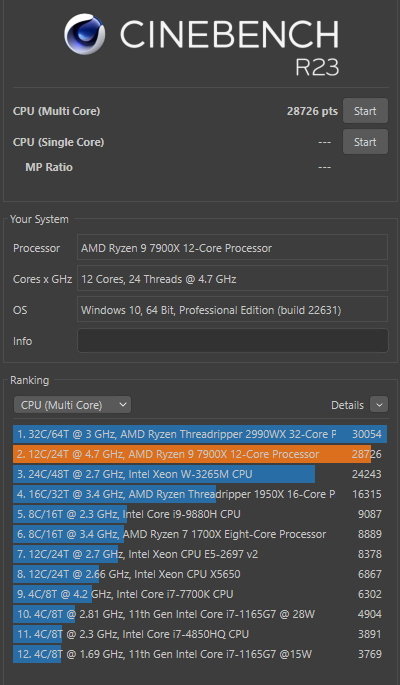
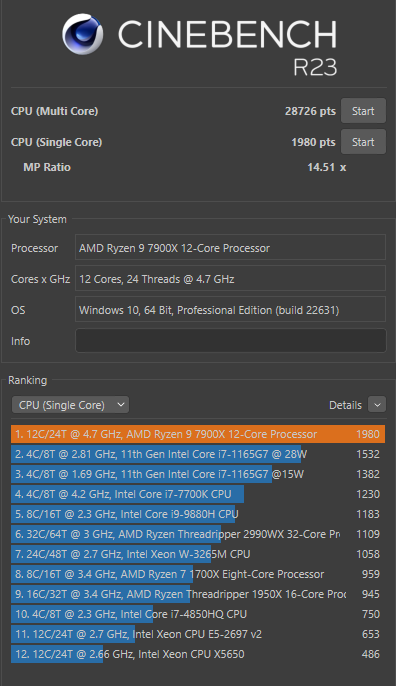
Wenn man diese Zahlen jetzt sieht, könnte man echt meinen, dass mein alter Intel gar nichts mehr geleistet hat. Wenn ich da irgendwas gestartet hätte, hätte ich den Jakobsweg komplett pilgern können und meine Frau hätte ein zweites Kind ausgetragen bevor da irgendwas weiter geht. Aber ganz ehrlich war der Rechner gar nicht so langsam.
Sicherlich spielt auch noch mit rein, dass bekanntlich Windows nach ein paar Jahren Einsatz einfach zugemüllt ist. Das hat sich in meinen Augen immer noch nicht verbessert und verfälscht sicherlich auch das Ergebnis, weil der neue Rechner natürlich komplett neu aufgesetzt ist.
Ich hab daher beschlossen, die Performance mit anderen - für mich praktischeren Zahlen zu vergleichen.
Ich hab die Software, an der ich beruflich arbeite genommen und die Compile-Zeit verglichen. Es handelt sich dabei um ein größeres Angular-Projekt, das zum Compilieren schon etwas aufwändiger ist. Nodetypisch hängt da die Zeit aber nicht nur von der CPU sondern auch von der Festplatte ab. Da ist natürlich die M.2 auch um einiges schneller als eine normale SSD, aber ich denke trotzdem, dass man so besser vergleichen kann.
Da ich diesen Vergleich ohnehin interessant finde, hab ich das gleiche auch mit mehreren Rechnern durchgeführt:
| AMD 7900X | Intel Core I5 6600K | Intel Core I7 4800MQ | Intel Core I7 5820K | Apple Pro M2 | |
|---|---|---|---|---|---|
| NEU | ALT | Thinkpad T540P | Dell Alienware Area 51 | Mac meines Kollegen | |
| real | 1m03,250s | 4m52,329s | 6m10,482s | 4m44,658s | 1m38,54s |
| usr | 1m57,134s | 6m23,232s | 7m46,321s | 0m0,153s | 204,52s |
| sys | 0m9,978s | 0m2,332s | 0m18,052s | 0m0,276s | 16,08s |
Also bei der Compilezeit (die erste Zeile ist das Interessanteste für mich), sieht man, dass der Unterschied definitiv da ist, aber weitem nicht so schlimm, wie das von Cinebench aussieht. Der I7 aus der Arbeit würde von der Zeit sicherlich auch noch viel mehr schaffen, aber wir haben im Büro alle das Gefühl, dass die Domäne und der installierte Virenscanner erheblich für Einbußen in der Performance verantwortlich ist.
Zudem sollte man auch erwähnen, dass ich bei meinen Systemen zu Hause unter Linux compiliert habe, während der I7 in der Arbeit unter Windows 10 läuft.
Fazit
Ich bin jedenfalls froh um den neuen Rechner. Mittlerweile ist auch alles wieder einigermaßen eingerichtet und es macht einfach Spaß mit ein bisschen mehr Performance an einem Rechner zu sitzen. Spiele hab ich ehrlich gesagt bis jetzt noch nicht ausprobiert, aber da muss ich noch schauen, was geht. Natürlich wird da die Grafikkarte dann der limitierende Faktor sein, aber ich denke trotzdem, dass ein bisschen mehr gehen wird, als früher.
]]>

